Introduction
DeepSeek V4 has been generating buzz since its launch three days ago, with initial testing results revealing surprising insights. With a staggering parameter count of 1.6 trillion and a context window of 1 million tokens, it offers API pricing significantly lower than GPT-5.5. Surprisingly, the entry-level Flash version outperformed the higher-end Pro in several real-world tasks.
Performance Testing: Flash Emerges as a Dark Horse
Many users instinctively test the most powerful model, but AI engineer Chew Loong Nian took a different approach. Within hours of DeepSeek V4’s release, he set up a testing framework with 20 real-world tasks, evaluating all four versions: V4-Pro, V4-Pro-Max, V4-Flash, and V4-Flash-Max.
DeepSeek V4 features two main product lines: Pro and Flash. Pro, with 1.6 trillion parameters, is designed for deeper reasoning and complex coding tasks, while Flash, with 284 billion parameters, is optimized for speed and cost-effectiveness. Users can also opt for a ‘deep thinking’ mode that enhances reasoning at the cost of slower response times.
The results were unexpected. The lightweight Flash model, costing approximately $0.14 per million tokens, won 7 out of 20 tasks, including 5 coding tasks. While Pro-Max generated more tokens, it often produced similar or worse results than Flash, highlighting that higher costs and deeper thinking do not always yield better outcomes.
Chew Loong Nian concluded that unless extreme depth of reasoning is essential, developers should prioritize Flash for most real-world applications. Its performance demonstrates that cost-effectiveness can be a powerful advantage.
Pro Version: Competing with Leading Closed-Source Models
Despite Flash’s success, the Pro version is not weak. DeepSeek V4-Pro aims to compete directly with top closed-source models. According to benchmark tests cited by MIT Technology Review, V4-Pro’s performance is comparable to Claude Opus 4.6, GPT-5.4, and Google Gemini 3.1. It excels over other open-source models in coding, math, and STEM problems, establishing itself as one of the most powerful open-source models.
However, some third-party evaluations still reveal a performance gap. A comparison by @thehypedotnews rated GPT-5.5 at 60, Claude Opus 4.7 at 57, and DeepSeek V4-Pro at 52, indicating a 13% performance deficit. Yet, the cost advantage is staggering: V4-Pro’s output price is only $1.73 per million tokens, significantly lower than its competitors.
During the initial 75% promotional discount, the price could drop to $0.87 per million tokens, making it 35 times cheaper than GPT-5.5 and 29 times cheaper than Claude Opus. This price-performance ratio shifts the competitive landscape.
Real-World Testing: Performance Under Pressure
Despite impressive cost metrics, the true test lies in real-world applications. The AI development team Build Fast with AI conducted a rigorous pressure test, requiring GPT-5.5, DeepSeek V4, and Claude Opus 4.7 to build a complete Pokémon-style battle engine from scratch.
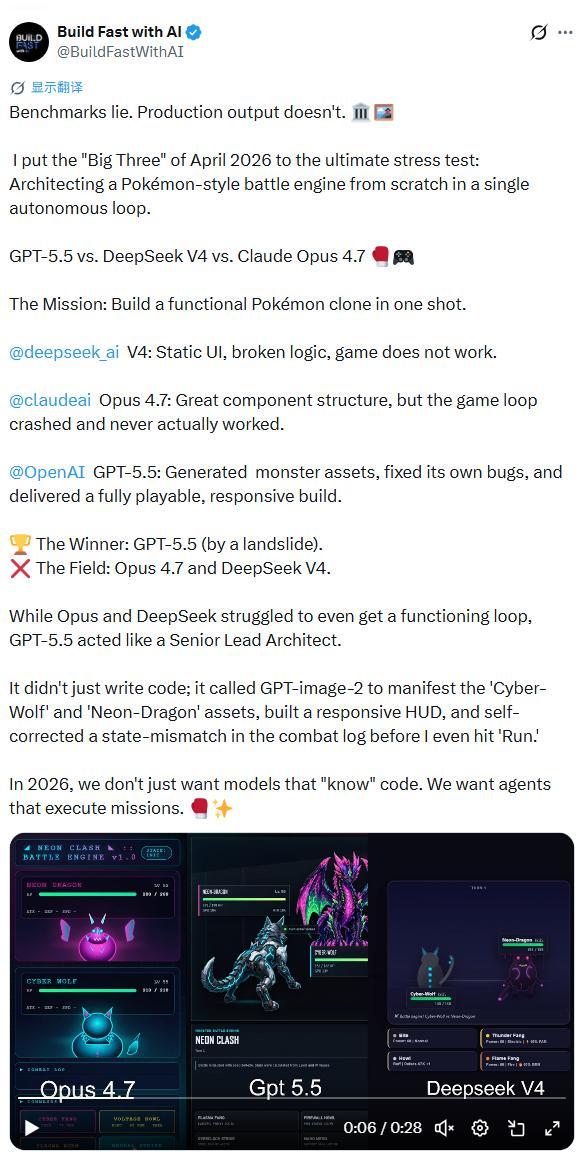
GPT-5.5 emerged as the clear winner, demonstrating superior coding capabilities and self-correcting issues before execution. Claude Opus performed well in component structure but failed to run the game, while DeepSeek V4 produced a non-functional static UI.
Similar challenges arose in quantitative trading tasks, where DeepSeek V4 struggled despite generating competent code. The model’s performance faltered in real market conditions, revealing its limitations in complex, unpredictable environments.
Long Context: A Key Advantage with Caveats
DeepSeek V4’s standout feature is its 1 million token context window, capable of handling extensive text. This innovation positions it alongside leading models like Gemini and Claude. However, the architecture’s efficiency is crucial; V4 uses significantly less computational power than its predecessor, allowing for practical applications in AI tools requiring vast amounts of data.
AI practitioner ByteWaveNetwork conducted a reproducible test, confirming V4’s mixed attention architecture improves retrieval stability in long contexts. However, he noted variability in response times, which could be problematic for production environments.
Strategic Implications: Moving Beyond Dependency
Beyond technical aspects, V4’s release signifies a strategic shift away from reliance on NVIDIA. It is the first model optimized for Chinese domestic chips, with Huawei’s Ascend 950 series providing comprehensive support for inference. This move suggests a potential reduction in costs as the hardware becomes more widely available.
DeepSeek’s approach reflects a broader trend in China’s AI ecosystem, transitioning from isolated models to a cohesive domestic technology stack. This evolution could reshape the competitive landscape, emphasizing cost reduction and self-sufficiency in AI development.
Conclusion
DeepSeek V4 is a distinctive model with strengths in long context processing, cost efficiency, and open-source flexibility. However, it reveals weaknesses in complex tasks compared to leading models like GPT-5.5 and Claude. It is not a one-size-fits-all solution; rather, it redefines the competitive landscape, emphasizing affordability and the potential for a self-sustaining AI ecosystem. For tasks requiring aesthetic judgment or intricate engineering, GPT-5.5 and Claude remain the safer choices. However, for long context analysis and cost-sensitive automation, DeepSeek V4 is an indispensable option.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.